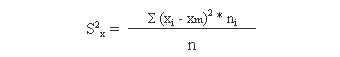| Menú Probabilidad y Estadística | Tema Anterior | Tema Siguiente |
a) Medidas de posición central
Las principales medidas de posición central son las siguientes:
1.- Media: es el valor medio ponderado de la serie de datos. Se pueden calcular
diversos tipos de media, siendo las más utilizadas:
a) Media aritmética: se calcula multiplicando cada valor por el número de veces
que se repite (su frecuencia absoluta simple). La suma de todos estos productos se divide por el total de datos
de la muestra:
|
|
Cuando todos los valores son diferentes, simplemente es la suma de estos dividida entre el total de datos.
b) Media geométrica: se eleva cada valor al número de veces que se ha repetido. Se multiplican todo estos resultados y al producto final se le calcula la raíz "n" (siendo "n" el total de datos de la muestra).
|
|
Según el tipo de datos que se analice será más apropiado utilizar la media aritmética o la media geométrica.
La media geométrica se suele utilizar en series de datos como tipos de interés anuales, inflación, etc., donde el valor de cada año tiene un efecto multiplicativo sobre el de los años anteriores. En todo caso, la media aritmética es la medida de posición central más utilizada.
Lo más positivo de la media es que en su cálculo se utilizan todos los valores de la serie, por lo que no se pierde ninguna información.
Sin embargo, presenta el problema de que su valor (tanto en el caso de la media aritmética como geométrica) se puede ver muy influido por valores extremos, que se aparten en exceso del resto de la serie. Estos valores anómalos podrían condicionar en gran medida el valor de la media, perdiendo ésta representatividad.
2.- Mediana: es el valor de la serie de datos que se sitúa justamente
en el centro de la muestra (un 50% de valores son inferiores y otro 50% son
superiores).
No presentan el problema de estar influido por los valores extremos, pero en
cambio no utiliza en su cálculo toda la información de la serie de datos (no
pondera cada valor por el número de veces que se ha repetido).
3.- Moda: es el valor que más se repite en la muestra.
Ejemplo: vamos a utilizar la tabla de distribución de frecuencias con los datos de la estatura de los alumnos que vimos en la lección 2ª.
| Variable | Frecuencias absolutas | Frecuencias relativas | ||
| (Valor) | Simple | Acumulada | Simple | Acumulada |
| 1,20 | 1 | 1 | 3,3 % | 3,3 % |
| 1,21 | 4 | 5 | 13,3 % | 16,6 % |
| 1,22 | 4 | 9 | 13,3 % | 30,0 % |
| 1,23 | 2 | 11 | 6,6 % | 36,6 % |
| 1,24 | 1 | 12 | 3,3 % | 40,0 % |
| 1,25 | 2 | 14 | 6,6 % | 46,6 % |
| 1,26 | 3 | 17 | 10,0 % | 56,6 % |
| 1,27 | 3 | 20 | 10,0 % | 66,6 % |
| 1,28 | 4 | 24 | 13,3 % | 80,0 % |
| 1,29 | 3 | 27 | 10,0 % | 90,0 % |
| 1,30 | 3 | 30 | 10,0 % | 100,0 % |
Vamos a calcular los valores de las distintas posiciones centrales:
1.- Media aritmética:
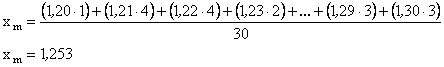 |
Por lo tanto, la estatura media de este grupo de alumnos es de 1,253 cm.
2.- Media geométrica:
| x = [(1,201)*(1,214)(1,224)*...(1,293)*(1,303)](1/30) x = 1,253 |
En este ejemplo la media aritmética y la media geométrica coinciden, pero no tiene siempre por qué ser así.
3.- Mediana:
La mediana de esta muestra es 1,26 cm, ya que por debajo está el 50% de los
valores y por arriba el otro 50%. Esto se puede ver al analizar la columna de
frecuencias relativas acumuladas.
En este ejemplo, como el valor 1,26 se repite en 3 ocasiones, la media se
situaría exactamente entre el primer y el segundo valor de este grupo, ya que
entre estos dos valores se encuentra la división entre el 50% inferior y el 50%
superior.
4.- Moda:
Hay 3 valores que se repiten en 4 ocasiones: el 1,21, el 1,22 y el 1,28, por lo
tanto esta seria cuenta con 3 modas.
Las medidas de posición no centrales permiten conocer otros puntos característicos de la distribución que no son los valores centrales. Entre otros indicadores, se suelen utilizar una serie de valores que dividen la muestra en tramos iguales:
Cuartiles: son 3 valores que distribuyen la serie de datos, ordenada de forma creciente o decreciente, en cuatro tramos iguales, en los que cada uno de ellos concentra el 25% de los resultados.
Deciles: son 9 valores que distribuyen la serie de datos, ordenada de forma creciente o decreciente, en diez tramos iguales, en los que cada uno de ellos concentra el 10% de los resultados.
Percentiles: son 99 valores que distribuyen la serie de datos, ordenada de forma creciente o decreciente, en cien tramos iguales, en los que cada uno de ellos concentra el 1% de los resultados.
Ejemplo: Vamos a calcular los cuartiles de la serie de datos referidos a la
estatura de un grupo de alumnos (lección 2ª). Los deciles y centiles se calculan
de igual manera, aunque haría falta distribuciones con mayor número de datos.
| Variable | Frecuencias absolutas | Frecuencias relativas | ||
| (Valor) | Simple | Acumulada | Simple | Acumulada |
| 1,20 | 1 | 1 | 3,3 % | 3,3 % |
| 1,21 | 4 | 5 | 13,3 % | 16,6 % |
| 1,22 | 4 | 9 | 13,3 % | 30,0 % |
| 1,23 | 2 | 11 | 6,6 % | 36,6 % |
| 1,24 | 1 | 12 | 3,3 % | 40,0 % |
| 1,25 | 2 | 14 | 6,6 % | 46,6 % |
| 1,26 | 3 | 17 | 10,0 % | 56,6 % |
| 1,27 | 3 | 20 | 10,0 % | 66,6 % |
| 1,28 | 4 | 24 | 13,3 % | 80,0 % |
| 1,29 | 3 | 27 | 10,0 % | 90,0 % |
| 1,30 | 3 | 30 | 10,0 % | 100,0 % |
1º cuartil: es el valor 1,22 cm, ya que por debajo suya se situa el 25% de la
frecuencia (tal como se puede ver en la columna de la frecuencia relativa
acumulada).
2º cuartil: es el valor 1,26 cm, ya que entre este valor y el 1º cuartil se
situa otro 25% de la frecuencia.
3º cuartil: es el valor 1,28 cm, ya que entre este valor y el 2º cuartil se
sitúa otro 25% de la frecuencia. Además, por encima suya queda el restante 25%
de la frecuencia.
Atención: cuando un cuartil recae en un valor que se ha repetido más de una
vez (como ocurre en el ejemplo en los tres cuartiles) la medida de posición no
central sería realmente una de las repeticiones.
Existen diversas medidas de dispersión, entre las más utilizadas podemos
destacar las siguientes:
1.- Rango: mide la amplitud de los valores de la muestra y se calcula por
diferencia entre el valor más elevado y el valor más bajo.
2.- Varianza: Mide la distancia existente entre los valores de la serie y la
media. Se calcula como sumatoria de las diferencias al cuadrado entre cada valor
y la media, multiplicadas por el número de veces que se ha repetido cada valor.
La sumatoria obtenida se divide por el tamaño de la muestra.
|
|
La varianza siempre será mayor que cero. Mientras más se aproxima a cero, más
concentrados están los valores de la serie alrededor de la media. Por el
contrario, mientras mayor sea la varianza, más dispersos están.
3.- Desviación típica: Se calcula como raíz cuadrada de la varianza.
4.- Coeficiente de variación de Pearson: se calcula como cociente entre la desviación típica y la media.
Ejemplo: vamos a utilizar la serie de datos de la estatura de los alumnos de una clase y vamos a calcular sus medidas de dispersión.
| Variable | Frecuencias absolutas | Frecuencias relativas | ||
| (Valor) | Simple | Acumulada | Simple | Acumulada |
| 1,20 | 1 | 1 | 3,3 % | 3,3 % |
| 1,21 | 4 | 5 | 13,3 % | 16,6 % |
| 1,22 | 4 | 9 | 13,3 % | 30,0 % |
| 1,23 | 2 | 11 | 6,6 % | 36,6 % |
| 1,24 | 1 | 12 | 3,3 % | 40,0 % |
| 1,25 | 2 | 14 | 6,6 % | 46,6 % |
| 1,26 | 3 | 17 | 10,0 % | 56,6 % |
| 1,27 | 3 | 20 | 10,0 % | 66,6 % |
| 1,28 | 4 | 24 | 13,3 % | 80,0 % |
| 1,29 | 3 | 27 | 10,0 % | 90,0 % |
| 1,30 | 3 | 30 | 10,0 % | 100,0 % |
1.- Rango: Diferencia entre el mayor valor de la muestra (1,30) y el menor
valor (1,20). Luego el rango de esta muestra es 10 cm.
2.- Varianza: recordemos que la media de esta muestra es 1,253. Luego,
aplicamos la fórmula:
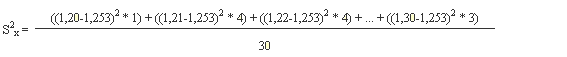 |
Por lo tanto, la varianza es 0,0010
3.- Desviación típica: es la raíz cuadrada de la varianza.
|
|
luego:
|
|
4.- Coeficiente de variación de Pearson: se calcula como cociente entre la desviación típica y la media de la muestra.
|
Cy = 0,.0320 / 1,253 Cy = 0,0255 |
El interés del coeficiente de variación es que al ser un porcentaje permite
comparar el nivel de dispersión de dos muestras. Esto no ocurre con la desvación
típica, ya que viene expresada en las mismas unidas que los datos de la serie.
Por ejemplo, para comparar el nivel de dispersión de una serie de datos de la
altura de los alumnos de una clase y otra serie con el peso de dichos alumnos,
no se puede utilizar las desviaciones típicas (una viene vienes expresada en m
y la otra en kg). En cambio, sus coeficientes de variación son ambos
porcentajes, por lo que sí se pueden comparar.
| Menú Probabilidad y Estadística | Anterior | Siguiente |